
The PROSIM Engine makes it possible to end-users like you to create your own OpenFoodFacts scoring database and to use it live in the OFF-graph website and App.
Once you have submitted your Computing Instance file (see below) and after its validation by Admins, you will shortly be able to perform the following tasks with your own database:
| [A] seeing my database's stats-record in the PROSIM blog | now available |
| [B] seeing statistics of my database (size, progression, number of intersections computed, etc.) | now available |
| [c] querying my database using the API | now available |
| [D] querying my own database by scanning the barcode of a product and getting matching-results in a OFF-graph | available on the test environment (clear Browser-Cache!) |
What do I need?
Knowledge
You need to have little knowledge in Java 8.Tools
You need an code editor such as vi or Visual Studio Code.Resources
OpenFoodFacts JSON API
Based on what you want to achieve, you need to match products properties which are defined in the
OpenFoodFacts JSON API, section Experimental
JSON
API (sample here).
Beware that not all properties are available in PROSIM; check next section to check what is available.
Template ComputingInstance.java
A file template for inserting your own code is available
here.
This is the exact code which is actually used for building the nutriscore database (on
5th oct. 2018). All
extra staff is performed by the PROSIM-Engine itself.
As you can see, not much code is required. Each part to fill in is described next.
As you can see, not much code is required. Each part to fill in is described next.
All you have to do is to download this file and fill each of the parts detailed below, and then submit it by mail
to the Admins for validation.
Sure, your file may contain mistakes, DO NOT WORRY ABOUT THIS : the Admins will perform some fix-up to make it work. You will be notified back of any changes in your code.
Sure, your file may contain mistakes, DO NOT WORRY ABOUT THIS : the Admins will perform some fix-up to make it work. You will be notified back of any changes in your code.
Refer to the table below to ensure which properties are available.
In case you absolutely need PROSIM to handle extra properties, feel free to make a request to Admins (by mail or
whatsoever).
Note: ProductExt in the file template inherits from Product shown here.
Properties of type Object (such as nutriments) can be used as follows through LinkedTreeMap mapping:
Note: ProductExt in the file template inherits from Product shown here.
Properties of type Object (such as nutriments) can be used as follows through LinkedTreeMap mapping:
this.nutrition_score_uk =
Float.parseFloat(((LinkedTreeMap)this.getNutriments()).get("nutrition-score-uk").toString());
Are you ready for the Jump?
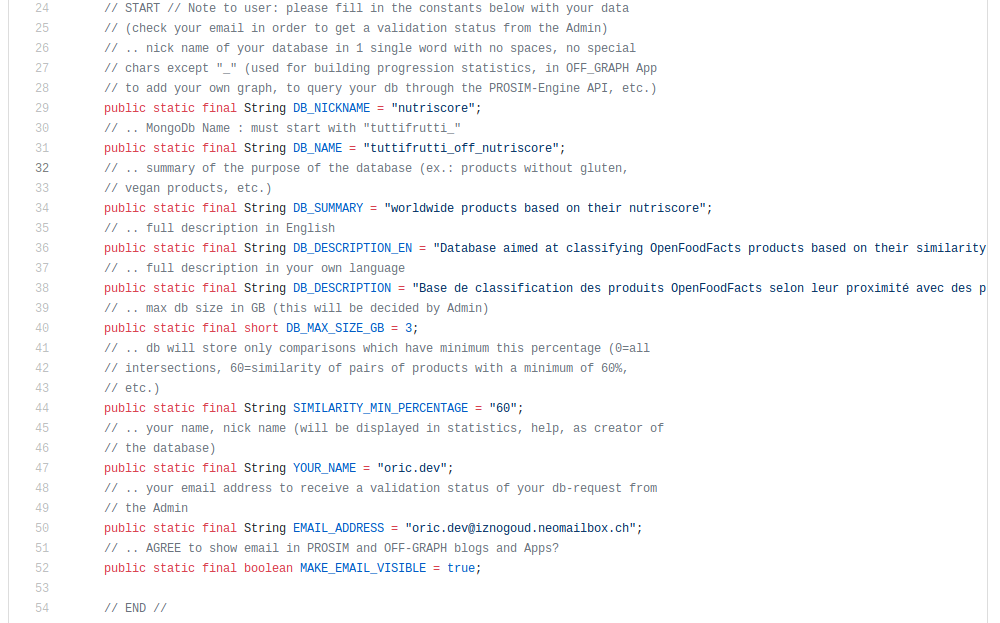
Fill in the constants
Compulsory information for you to fill in are listed below. These information will be visible to anybody in the
above [B]-link:
- DB_NICKNAME: nickname for your database. It must be unique along all niknames already defined
(check in link provided in [C] above). Please use only alphabetic or numerical digits. Underscore
("_") is also allowed but no other signs.
Choose the nickname based on the purpose of your db. The name may be in your own language if you wish but then prefix it preferably with the country code.
Here are some examples: nutriscore_fr, nutriscore_de, novascore_br, vegan, fr_nutri_sans_allergenes. - DB_DISPLAY_NAME: human readable name to be displayed in a graph for instance (e.g. OFF-Graph).
- DB_SUMMARY: purpose of your database in English language. Make it short but provide comprehensible details.
- DB_DESCRIPTION_EN: full description of your database in English language. Tell us what it is all about!
- SIMILARITY_MIN_PERCENTAGE: provide a minimum proximity/similarity Percentage under which a pair
of products {A; B} will be ignored and not stored in your database (threshold). If a pair is ignored,
this DOES NOT
mean that A and B will not be stored at all, it just means that if you query product A or B (API,
OFF_GRAPH), the counterpart product will not appear because they are to far from each other (below
threshold).
In practice, once PROSIM retrieves the result of yout computeSimilarity below, it discards the pair if threshold is not reached.
Hence, if you want a database with all pairs, set the threshold to "0" (0%). If you wish only relevant matching products, set the threshold closer to "100" (100%).
Default value "60" (60%) appears in real life to be quite low enough, so a range [60; 75] seem to provide interesting results. - SCORE_MIN_VALUE: minimum value for the scores.
- SCORE_MAX_VALUE: maximum value for the scores.
- SCORE_LABEL_Y_AXIS: label to display in the graph for score values.
- BOTTOM_UP: set it to True if the maximum value is oriented at the top of the graph; either False.
- SCORE_NB_INTERVALS: number of intervals between the min. and the max. values (number of stripes to show).
- SCORE_INTERVALS_STRIPE_COLOUR: RGB(A) colours for each stripe of the graph from min. value to max. value.
- SCORE_INTERVALS_LABELS: Y-axis labels for each stripe of the graph from min. value to max. value.
- YOUR_NAME: give your name, nickname, pet name, something to call you with
- EMAIL_ADDRESS: provide an email address so that Admins can give an answer back regarding your database submission
- MAKE_EMAIL_VISIBLE: if set to "false", your email address only will be kept secret, and will only be used by Admins to contact you if necessary
All other fields are optional and may be ignored by the Admins when they create your database.
Filter your products
Filtering products which appear in your database is an important step. If you leave the method returning
"true", this means that all "valid" OpenFoodFacts products (with categories and a score) will be taken into
account.
But you may also want to restrict the set of products to those of your country (countries_tags), or without allergens (having allergens_tags empty), etc.
This is the place where you can restrict products to your community's needs!
But you may also want to restrict the set of products to those of your country (countries_tags), or without allergens (having allergens_tags empty), etc.
This is the place where you can restrict products to your community's needs!

Computation of the proximity between 2 products
This method provides a computation for the proximity between 2 products. How to know if product A is similar to
another product B?
You may want to use labels, ingredients, categories, or even a mix of several information.
By default, the proximity/similarity between products is based on the intersection of their categories. Just to make it short, it is similar to the computation of the probability of 2 statistical dependent events. In practice, this means that the distance between A towards B may be sometimes different from the distance of B towards A. Check here for more details.
As a conclusion: you may not need to update this method, but of course you are also free to do so.
You may want to use labels, ingredients, categories, or even a mix of several information.
By default, the proximity/similarity between products is based on the intersection of their categories. Just to make it short, it is similar to the computation of the probability of 2 statistical dependent events. In practice, this means that the distance between A towards B may be sometimes different from the distance of B towards A. Check here for more details.
As a conclusion: you may not need to update this method, but of course you are also free to do so.

Computation of the score of a product
Write downhere the code for computing the score of a product. Typically, this will be a nutritional
scoring in your country (United Kingdom, Germany, France, ...) or even your own scoring.
The code shown here in the template sample stands for the computation of the nutriscore (french nutritional scoring) in his older form since it has been reviewed recently (check here for the formulas).
You are strongly encouraged to adapt the code to your country, needs, communities.
The value returned is typically shown in the tuttifrutti website on the vertical axis. By using the API ([B] above), you may use it anyhow you like.
Check at the end of this page for some scoring made available indifferent countries.
The code shown here in the template sample stands for the computation of the nutriscore (french nutritional scoring) in his older form since it has been reviewed recently (check here for the formulas).
You are strongly encouraged to adapt the code to your country, needs, communities.
The value returned is typically shown in the tuttifrutti website on the vertical axis. By using the API ([B] above), you may use it anyhow you like.
Check at the end of this page for some scoring made available indifferent countries.

Hey, I have finished. What do I do now?
When you are finished, send the file computingInstance.java to the email address mentioned in the header
of the file and wait for a response from the Admins.
If your file is accepted, you will receive a mail back with extra links for viewing statistics of your database, access it through API, and so on and so forth.
If your file is accepted, you will receive a mail back with extra links for viewing statistics of your database, access it through API, and so on and so forth.
Thanks for the fish...!
Further reading:
feel free to suggest links to other scoring (Nova, UK, etc.). They will be added here. Thanks :) !
Commentaires
Enregistrer un commentaire